欧洲杯体育径直把Transformer里本来就有的MLP模块-开云(中国)kaiyun体育网址-登录入口

鱼羊 发自 凹非寺
量子位 | 公众号 QbitAI
字节Seed最新权术,让大模子能“原地改参数”了。
既无谓改模子结构,也无谓从新查考,还跑得很快。

具体是这样个情况。智能体期间嘛,世界都知谈模子们濒临的任务运行变得越来越复杂、凹凸文越来越长。
怎样让大模子边干活边学习,不休合乎新的信息,而不是在超长凹凸文中逐渐崩溃,一经成为AI圈权术的一大约点。
测试时查考(TTT)让模子简略在推理时更新部分参数,但现实应用时,问题仍然很复杂:
领先,架构不兼容。现存的TTT需要引入全新的收集层,以至替换看重力机制,导致必须重新运行作念预查考。
其次,诡计后果低。现存的TTT接收一个Token一个Token的礼貌更新,无法充分足下GPU/TPU的并行诡计才气。
还有优化打算不匹配的问题。现存TTT多接收重建打算(reconstruction),只让模子记着面前的词,而不是为了瞻望下一个词遐想。也即是说,与说话模子中枢的“瞻望下一个Token”的任务不匹配。
针对这些问题,来自字节Seed和北京大学的权术团队思到了一个小妙招:
不新增层,也不改架构,径直把Transformer里本来就有的MLP模块,当成大模子的“临时小脑”。
这个名为In-Place TTT(原地测试时查考)的决策,让TTT不错算作即插即用的模块,无缝集成到现存的预查考大模子中。
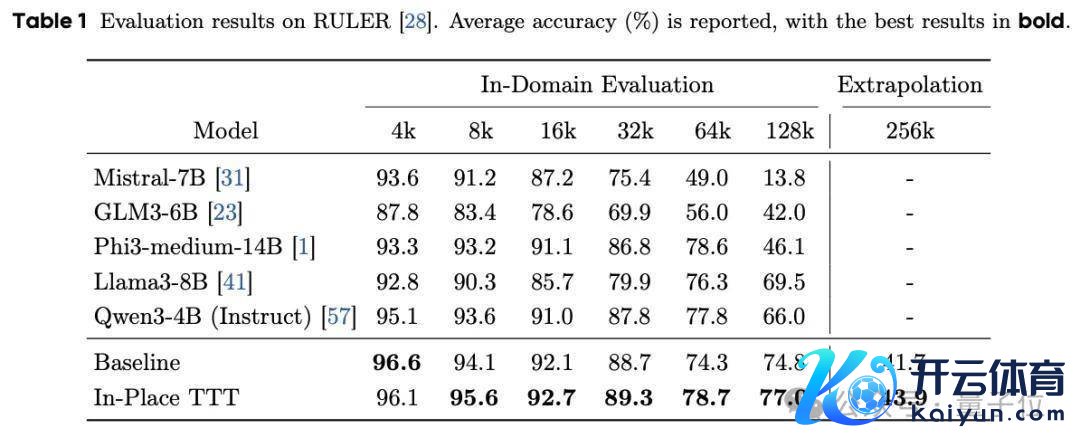
实考阐明,Qwen3-4B、Llama3.1-8B、Qwen3-14B在装备In-Place TTT之后,都原地变强了,况兼在长文本任务上进步尤为光显。
这篇论文一经中了ICLR 2026 Oral。
让大模子在推理时“原地改参数”话未几说,照旧来看论文的详备内容。
In-Place TTT中枢要科罚的问题,是在不折腾模子架构的前提下,让大模子在推理/恢复问题时,也能暗暗更新我方,适配面前的凹凸文。
终了即插即用,字节Seed和北大的权术东谈主员主要作念了3点创新。
原地架构遐想在In-Place TTT中,权术东谈主员玄机地复用了Transformer中无处不在的MLP(多层感知机)。
他们将MLP的临了一个投影矩阵Wdown算作快速权重(fast weights),在推理时进行原地更新。
这样就无需引入新的专用层来处理快速权重。一经训好的大模子也不错拿来径直用,不必从新查考。
说话模子对皆的优化打算
原本的TTT只让模子“记着面前Token”,前文一经提到,这与说话模子的优化打算是不一致的。
为此,In-Place TTT遐想了挑升针对自转头说话模子的优化打算:
通过引入一维卷积(Conv1D)和投影矩阵,使TTT的打算值包含了将来 Token的信息,从而显式地与“瞻望下一个Token”的任务对皆。
权术东谈主员还分析阐明,这种作念法能促使快速权重压缩对将来瞻望有用的信息,从而灵验进步模子的凹凸文体习才气。
高效的块级更新机制In-Place TTT是对MLP进行立异,保留了原有的看重力层,这就使得该措施不错终了分块更新,无谓再逐Token去向理。
协调凹凸文并行本领,In-Place能终了更高的微辞量和诡计后果,复古更长的凹凸文。
实验标明,In-Place TTT能大幅进步现存模子(如Qwen3-4B)在128K以至256K长凹凸文任务中的贯通。
在重新查考的对比中,也优于其他TTT措施。
权术团队
In-Place TTT的论文一作是冯古豪和罗胜杰。
冯古豪当今就读于北京大学,是字节Seed的实习生。
罗胜杰相同毕业于北大,师从王立威教养和本文通信作家贺笛教养。
本文的另一位通信作家是字节Seed的Wenhao Huang。
论文地址:
https://arxiv.org/abs/2604.06169v1